

In a previous post I talked about my “hobby project” of compiling color statistics from each year’s runway fashion collections.
I’ve typically done this manually, but this time I also wondered if the process could be automated with GPT-4.
So I tried it! I wrote a script to:
download all images from Vogue Magazine’s coverage of the Spring/Summer 2024 ready-to-wear collections
for each image, make an API call to OpenAI’s GPT-4-vision-preview model with the query “Give a bulleted list of the specific shades of color present in this outfit”
compile statistics on the frequency of each color name across all the images.
You can see my Jupyter notebook here — I might clean it up later on.
A Few Observations:
The limit for GPT-4 Vision Preview is capped at 1500 requests per day and rate-limited at 120 requests per minute. At over 12,000 images total, this was impractical, so I just had it wait 60s between requests and run over several days.
Querying GPT-4 Vision Preview about image colors was fairly accurate, but many (~5-10%) queries came up empty, with something like “I’m sorry, but I am not able to assist with that request.” Rerunning the same queries on the same images sometimes gave results; it seems like a random effect.
Vision Preview did sometimes make mistakes like including background or hair colors, and sometimes made color judgment calls differently than I would, but nothing egregious; I wouldn’t be surprised if it was as accurate as a human scorer.
Of course, if you simply count the frequency of distinct auto-generated “color names” you get synonym effects, like “grey” and “gray” being counted as two different colors. Or “deep red” and “dark red”, “light blue” and “pale blue”, etc. There’s no principled way to consolidate synonyms so I left them as-is, but keep in mind that synonym effects could meaningfully affect the rank order of color frequencies.
The Vision Preview responses often contained a lot of extraneous text and summary, so I used a secondary “cleanup” query to GPT-4, with the prompt "Please extract all the color names from the following text, and return a comma-separated list of ONLY the color names in the text. If a color name appears multiple times, repeat it for each time it appears in the text. Only use lower-case letters." This fairly reliably converted the text into a comma-separated list of color names, although there were a few cases where non-color words or phrases (like “I’m sorry”) were erroneously picked up.
Results

The most common colors, unsurprisingly, were neutrals: black, white, and an interesting pale range of cream, off-white, beige, and metallic silver and gold.
If we restrict attention just to non-neutral colors, we get the following top-thirty:

Basic “red” at the top, unsurprisingly — followed by a familiar angelic palette of pastel pinks and light blues, punctuated by green, yellow, and the darker autumnal tones of olive green and burgundy.
This isn’t hugely different from my manually-scored version, if you keep in mind synonym effects.1
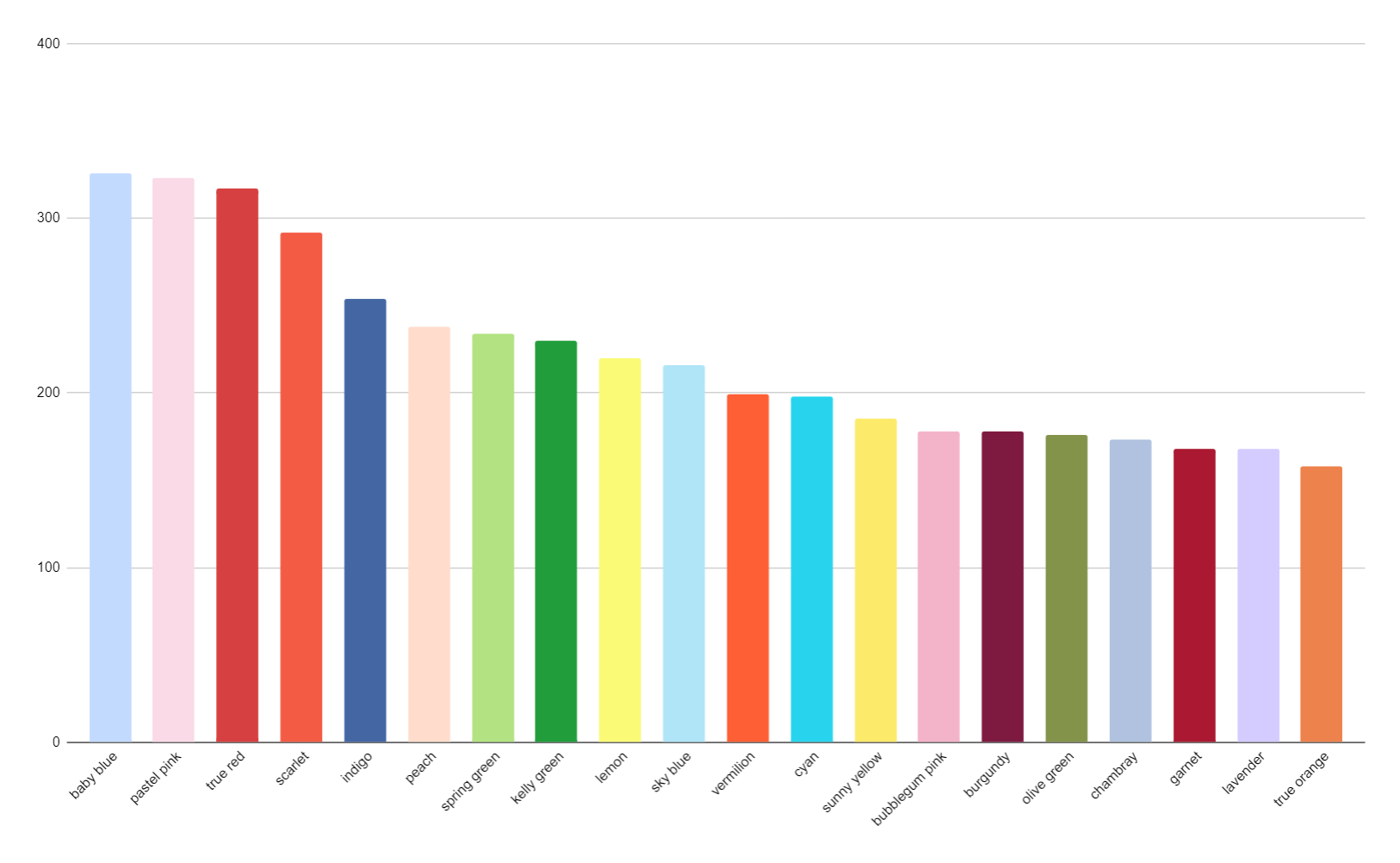
There’s a lot more olive green in the automated color stats than the manual, and that does seem like a real effect.2 Is it just “noise”, luck of the draw that would disappear in a repeat attempt? Or does GPT-4 have a systematic affection for olive green?
I don’t know, and until OpenAI raises their daily API caps I don’t particularly feel like rerunning the whole saga.
Spring green, which was my manual pick for a “color of the year”, didn’t show up at all verbatim in the GPT-4 top-30, and its near neighbors (“light green” and “lime green”) only barely squeaked in, but this might be a synonym effect — the same color can easily be called “chartreuse”, “light chartreuse”, or even simply “green”.
Bottom line is there’s less overlap between manual and automated scoring than I’d like, and automated scoring is slow enough that it’s hard for me to know how much of that is simply a result of e.g. the ~10% of API calls that come up empty.
Insights
One lesson learned here is that LLMs really are stochastic. A query that “just works” in a couple of spot checks, will refuse to respond at all some percent of the time, and will very occasionally return totally unexpected nonsense, if you run it tens of thousands of times.3 “Normal” computer programs do not do this. Exception handling, I would imagine, needs to be approached in a whole new way when “unexpected” behavior can be so varied.4
Another lesson learned is about psychology — it’s amazing how I found myself shifting from a pretty neutral attitude towards OpenAI to an enthusiastic fangirl eagerly awaiting a higher daily request cap, just as a result of using the API for a hobby project. Suddenly OpenAI is my buddy, my pal, the source of all delight, the faucet from which I eagerly slurp. I am sure this must be a well-known effect and part of the reason software companies cultivate developer communities, but I’ve never experienced it so dramatically myself.
The “baby blue” of my manual count might be equivalent to GPT’s “light blue” and “pale blue”; the “pastel pink”of my manual count might might correspond to GPT’s “light pink” and “pale pink”; the “true red” and “scarlet” of my manual count might correspond to GPT’s “red” and “bright red”; so the rank ordering of red, pastel pink, and pastel blue doesn’t seem significantly different between them.
a few spot checks suggest that GPT-4 tended to code things as “olive green” that I might have read as brown or a different shade of green, but it’s not obviously an error, just a rather expansive definition of “olive.”
One image description returned the totally unrelated text: “The red car passed by the blue house. His green eyes were beautiful. The yellow banana was ripe. He wore a white shirt. He loved her brown hair. My pink phone case is awesome. He kicked the black ball. She liked the purple flower. His favorite color was orange.”
how would you implement “rerun the Vision Preview query if it fails to return an image description” and be sure to catch all the “I’m sorry, I can’t…” type responses when there are so many different phrasings of those? I’m not sure and I didn’t bother.
“Suddenly OpenAI is my buddy, my pal, the source of all delight, the faucet from which I eagerly slurp.” 💀💀💀
Separately, re: needing to extract color names, you can do this in a single pass via function calling. That’s the best way to get structured/clean output from the model.